PunktSentenceTokenizer
Split text into sentences “by using an unsupervised algorithm to build a model for abbreviation words, collocations, and words that start sentences.”
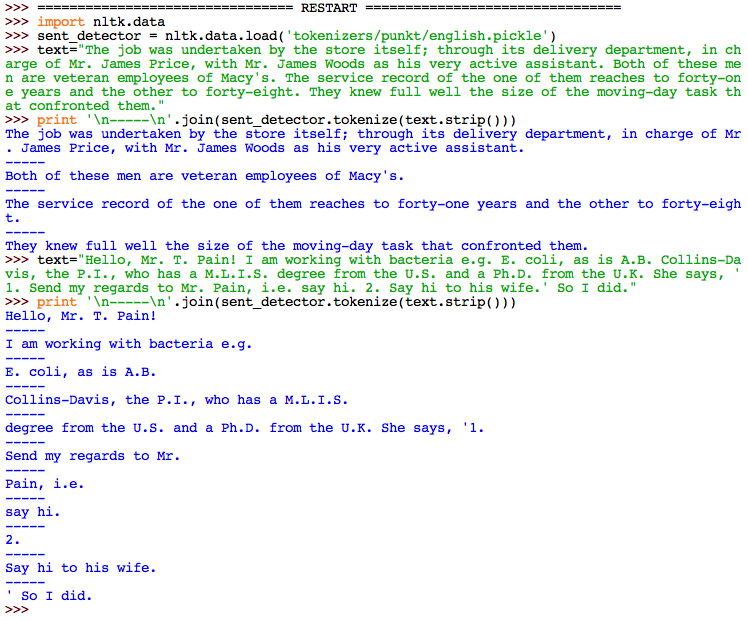
ref:
Sentence Tokenize
>>> text = “this’s a sent tokenize test. this is sent two. is this sent three? sent 4 is cool! Now it’s your turn.”
>>> from nltk.tokenize import sent_tokenize
>>> sent_tokenize_list = sent_tokenize(text)
>>> len(sent_tokenize_list)
5
>>> sent_tokenize_list
[“this’s a sent tokenize test.”, ‘this is sent two.’, ‘is this sent three?’, ‘sent 4 is cool!’, “Now it’s your turn.”]
>>>
ref: